
Datos sintéticos, anclados en evidencia humana.
Aceleramos la investigación con IA para generar datasets sintéticos que reproducen los patrones reales del mercado, con un objetivo claro: llegar antes a conclusiones accionables y reservar el fieldwork humano para lo que realmente lo requiere.
Qué son
Los datos sintéticos son información generada mediante modelos de IA que replica la estructura estadística y las relaciones observadas en datos de investigación real (muestra humana), sin copiar registros individuales.
Cómo lo hacemos
Nuestra aproximación combina dos pilares:
- Modelos probabilísticos (muestreo aleatorio y modelado de dependencias) para preservar relaciones clave.
- Modelos de deep learning (enfoque no supervisado combinando arquitecturas tipo GAN/VAE) para generar datasets sintéticos robustos.
No desarrollamos bases de datos “from scratch”. Nuestro enfoque exige como punto de partida un dataset real de origen humano.
Cómo se configura
LO QUE NECESITA EN LA MEDIDA JUSTA
Cada proyecto se define en tres pasos:
- Base de entrenamiento / referencia: estudios históricos o datasets de alta calidad disponibles.
- Definición del reto de negocio: qué decisión se va a tomar (y qué variables deben sostenerla).
- Reglas de control (guardrails): qué relaciones deben preservarse (segmentos, uso, actitudes…) y qué se excluye para evitar ruido o sensibilidad.
Calidad y credibilidad:
Para garantizar que el resultado es fiable y utilizable, cada modelo incluye un paquete de validación con:
- Distribuciones y comportamiento univariable (comportamiento de cada variable).
- Distribuciones y análisis bivariable (relaciones condicionales entre variables).
- Distribuciones y análisis Multivariable (Homegeneidades, ADM, PCA comparativa, Clustering stability (ARI), RMSE, Adversarial test)
- Correlaciones (estructura de relaciones matricial).
- Distancias (proximidad sintética vs. Original con Maximum Mean Discrepancy (MMD) y Jensen-Shannon distance).
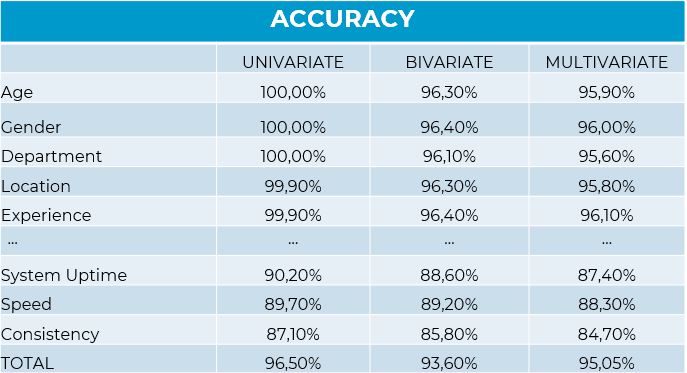
*La precisión de los datos sintéticos no se evalúa mediante una simple comparación de medias. Se analiza en tres niveles clave: la preservación de la estructura relacional, la estabilidad de los segmentos y la robustez predictiva en validaciones cruzadas. Cuando un modelo entrenado con datos sintéticos es capaz de predecir con fiabilidad datos reales, podemos hablar de equivalencia operativa.
Dónde SÍ aporta valor
- Innovación y concept/claim screening: priorizar ideas antes de una validación humana completa.
- Cobertura de targets difíciles / muestras pequeñas: “rellenar huecos” cuando el sample humano no llega o es caro.
- Velocidad y agilidad: generar escenarios y lecturas preliminares en menos tiempo.
- Simulación: explorar situaciones raras o poco frecuentes que cuesta capturar en la realidad.
Cuando NO lo recomendamos
- Cuando necesitas insight fresco y de primera mano (crisis, cambios abruptos del mercado).
- Cuando no existe una base de referencia sólida para entrenar/ancorar el modelo.
- Cuando la decisión exige evidencia humana por motivos regulatorios/legales.
En estos casos puede utilizarse como pre-análisis, pero no como sustituto del fieldwork humano.
