
Synthetic data, anchored in human evidence.
We accelerate research with AI to generate synthetic datasets that reproduce real market patterns, with a clear objective: to reach actionable conclusions faster and reserve human fieldwork for what really requires it.
What are they?
Synthetic data is information generated by AI models that replicates the statistical structure and relationships observed in real research data (human sample), without copying individual records.
How we do it
Our approach combines two pillars:
- Probabilistic models (random sampling and dependency modeling) to preserve key relationships.
- Deep learning models (unsupervised approach combining GAN/VAE type architectures) to generate robust synthetic datasets.
We do not develop databases "from scratch". Our approach requires a real, human-generated dataset as a starting point.
How to configure
WHAT YOU NEED IN JUST THE RIGHT AMOUNT
Each project is defined in three steps:
- Training base / reference: historical studies or high-quality datasets available.
- Defining the business challenge: what decision will be made (and what variables should support it).
- Control rules (guardrails): what relationships should be preserved (segments, use, attitudes…) and what is excluded to avoid noise or sensitivity.
Quality and credibility:
To ensure that the result is reliable and usableEach model includes a validation package with:
- Distributions and univariate behavior (behavior of each variable).
- Distributions and bivariate analysis (conditional relationships between variables).
- Multivariate Distributions and Analysis (Homegeneities, ADM, comparative PCA, Clustering stability (ARI), RMSE, Adversarial test)
- Correlations (matrix relationship structure).
- Distances (synthetic proximity vs. original with Maximum Mean Discrepancy (MMD) and Jensen-Shannon distance).
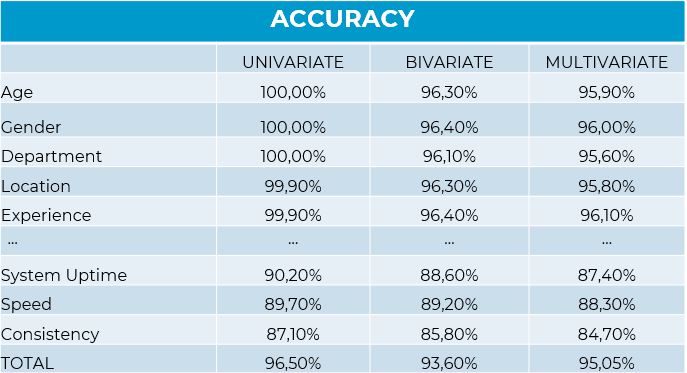
The accuracy of synthetic data is not evaluated by a simple comparison of means. It is analyzed at three key levels: the preservation of relational structure, the stability of segments, and predictive robustness in cross-validations. When a model trained on synthetic data is able to reliably predict real-world data, we can speak of operational equivalence.
Where YEAH adds value
- Innovation and concept/claim screening: prioritize ideas before full human validation.
- Coverage of difficult targets / small samples: “filling gaps” when the human sample is unavailable or expensive.
- Speed and agility: generate scenarios and preliminary readings in less time.
- Simulation: explore rare or infrequent situations that are difficult to capture in reality.
When NO We recommend it
- When you need insight cool and firsthand (crisis, abrupt market changes).
- When there is no baseline solid for training/anchoring the model.
- When the decision requires human evidence for reasons regulatory/legal.
In these cases it can be used as pre-analysisbut not as a substitute for human fieldwork.
