
Dades sintètiques, ancorades en evidència humana.
Accelerem la investigació amb IA per generar datasets sintètics que reprodueixen els patrons reals del mercat, amb un objectiu clar: arribar abans a conclusions accionables i reservar el fieldwork humà per allò que realment ho requereix.
Què són
Les dades sintètiques són informació generada mitjançant models dIA que replica lestructura estadística i les relacions observades en dades de recerca real (mostra humana), sense copiar registres individuals.
Com ho fem
La nostra aproximació combina dos pilars:
- Models probabilístics (mostreig aleatori i modelatge de dependències) per preservar relacions clau.
- Models de deep learning (enfocament no supervisat combinant arquitectures tipus GAN/VAE) per generar datasets sintètics robusts.
No desenvolupem bases de dades “from scratch”. El nostre enfocament exigeix com a punt de partida un dataset real d'origen humà.
Com es configura
EL QUE NECESSITA A LA MESURA JUSTA
Cada projecte es defineix en tres passos:
- Base d'entrenament/referència: estudis històrics o datasets d'alta qualitat disponibles.
- Definició del repte de negoci: quina decisió es prendrà (i quines variables han de sostenir-la).
- Regles de control (guardrails): quines relacions s'han de preservar (segments, ús, actituds…) i què s'exclou per evitar soroll o sensibilitat.
Qualitat i credibilitat:
Per garantir que el resultat és fiable i utilitzable, cada model inclou un paquet de validació amb:
- Distribucions i comportament univariable (comportament de cada variable).
- Distribucions i anàlisi bivariable (relacions condicionals entre variables).
- Distribucions i anàlisi Multivariable (Homegeneïtats, ADM, PCA comparativa, Clustering stability (ARI), RMSE, Adversarial test)
- Correlacions (estructura de relacions matricial).
- Distàncies (proximitat sintètica vs. Original amb Maximum Mean Discrepancy (MMD) i Jensen-Shannon distance).
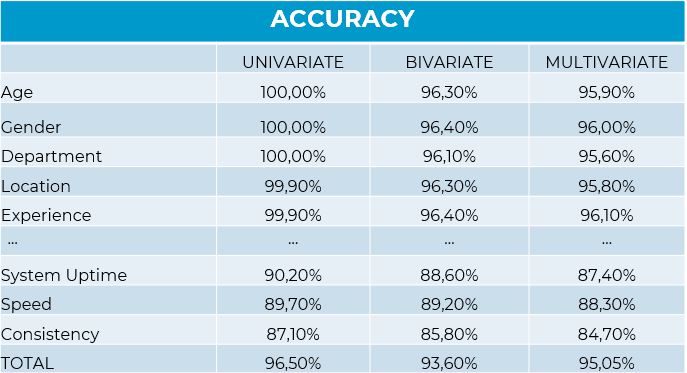
*La precisió de les dades sintètiques no s'avalua mitjançant una simple comparació de mitjanes. S‟analitza en tres nivells clau: la preservació de l‟estructura relacional, l‟estabilitat dels segments i la robustesa predictiva en validacions creuades. Quan un model entrenat amb dades sintètiques és capaç de predir amb fiabilitat dades reals, podem parlar d'equivalència operativa.
On SÍ aporta valor
- Innovació i concept/claim screening: prioritzar idees abans d'una validació humana completa.
- Cobertura de targets difícils / mostres petites: “omplir buits” quan el sample humà no arriba o és car.
- Velocitat i agilitat: generar escenaris i lectures preliminars en menys temps.
- Simulació: explorar situacions rares o poc freqüents que costa capturar a la realitat.
Quan NO ho recomanem
- Quan necessites insight fresc i de primera mà (crisi, canvis abruptes del mercat).
- Quan no n'hi ha una base de referència sòlida per entrenar/ancorar el model.
- Quan la decisió exigeix evidència humana per motius regulatoris/legals.
En aquests casos es pot utilitzar com a pre-anàlisi, però no com a substitut del fieldwork humà.
